Can Reddit Predict the Stock Market? We Tried to Find Out.
Can Reddit Predict the Stock Market? We Tried to Find Out.
A team project exploring whether WallStreetBets sentiment holds any predictive power over S&P 500 price movements.
Why We Thought This Might Work
There's a running joke in investing that a dart-throwing monkey can outperform Wall Street analysts. We wanted to know if the collective wisdom (or chaos) of Reddit's r/WallStreetBets could do any better.
WallStreetBets is one of the most influential retail investing communities on the internet. Its users post daily about trades, market vibes, and often unhinged financial takes. The subreddit exploded into mainstream consciousness during the 2021 GameStop short squeeze, proving that under the right conditions, it could genuinely move markets.

So we had a simple question: if we could measure the mood on WallStreetBets on any given day, could that help us predict what SPY would do the next day? The thinking was that crowd sentiment might act as a leading indicator. Bullish posts today might mean a green day tomorrow.
We want to be upfront: we didn't go into this expecting to build a money printer. The real goal was experimentation. Could we build the full data pipeline? And what would the data actually tell us once we did?
Pulling Together the Data
We needed two datasets. First, post titles from WallStreetBets. Second, historical SPY close prices.
For stock data, we used the yfinance Python library to pull daily close prices from Yahoo Finance. We grabbed about a year's worth of data, from April 2022 through April 2023. From those prices we computed a "delta" for each day, basically just the price change from one close to the next. Then we sorted each delta into buckets ranging from "extremely positive" (more than +$10) down to "extremely negative" (less than -$10), with finer categories in between.
For the Reddit side, we used the Pushshift API to scrape post titles from r/WallStreetBets. Each batch of posts had to line up with a specific trading day, so there was a lot of back-and-forth converting between Unix timestamps and normal calendar dates. We wrote helper functions to figure out "days before" and "days after" each stock date, and then queried Pushshift with those time windows.
The scraping process was bumpy, to put it nicely. Pushshift has rate limits and goes down sometimes, so we built in resume logic. If the script crashed halfway through, it could pick up where it left off instead of re-scraping everything from scratch.
TextBlob Sentiment Analysis
Our first approach was the most obvious one. We used TextBlob, a simple NLP library, to score each post title on a scale from -1 (negative) to +1 (positive). The idea was dead simple: run every post title through the sentiment analyzer, average the scores for each day, and see if that daily score tracked with price movement.
We plotted the daily sentiment scores against SPY's close price and fit a regression line through it.
The result was, well, nothing. A barely visible positive slope with data points scattered everywhere. The scatter plot looked like someone sneezed on a canvas. There was no meaningful relationship between what TextBlob was picking up and where prices actually went.
Why TextBlob fell short: WallStreetBets posts are loaded with slang, sarcasm, and financial jargon that TextBlob simply doesn't understand. A post titled "SPY puts are free money" reads as neutral or mildly positive to the algorithm, but anyone on WSB knows that's a bearish bet.
The Pivot: Universal Sentence Encoder
So we threw out the TextBlob approach and reached for something with a lot more firepower: Google's Universal Sentence Encoder. Instead of boiling a post title down to a single sentiment number, USE converts each sentence into a 512-dimensional embedding vector. That's a dense mathematical representation that captures way more meaning than a polarity score ever could.
The key insight behind this change was to skip the intermediate "sentiment" step altogether. Instead of going from post to sentiment score to price prediction, we'd go straight from post to embedding vector to price prediction. Let the model itself figure out which dimensions of meaning correlate with price movement, assuming any correlation exists at all.
Switching from LSTM to RNN
We originally planned to use an LSTM network (Long Short-Term Memory), which is the standard go-to for time series and sequential data. LSTMs are great at capturing long-term patterns, and they're commonly used in financial forecasting and language modeling.
But we ran into a practical wall. LSTMs are hungry for data, and our dataset of roughly 252 trading days just wasn't big enough for the network to learn anything useful. On top of that, the data was extremely noisy. Markets are influenced by hundreds of variables at once, and Reddit post titles represent a tiny sliver of the overall picture.
So we simplified. We switched to a basic RNN (Recurrent Neural Network) architecture, which is better suited for finding patterns in smaller, noisier datasets without overfitting as badly.
The Verdict
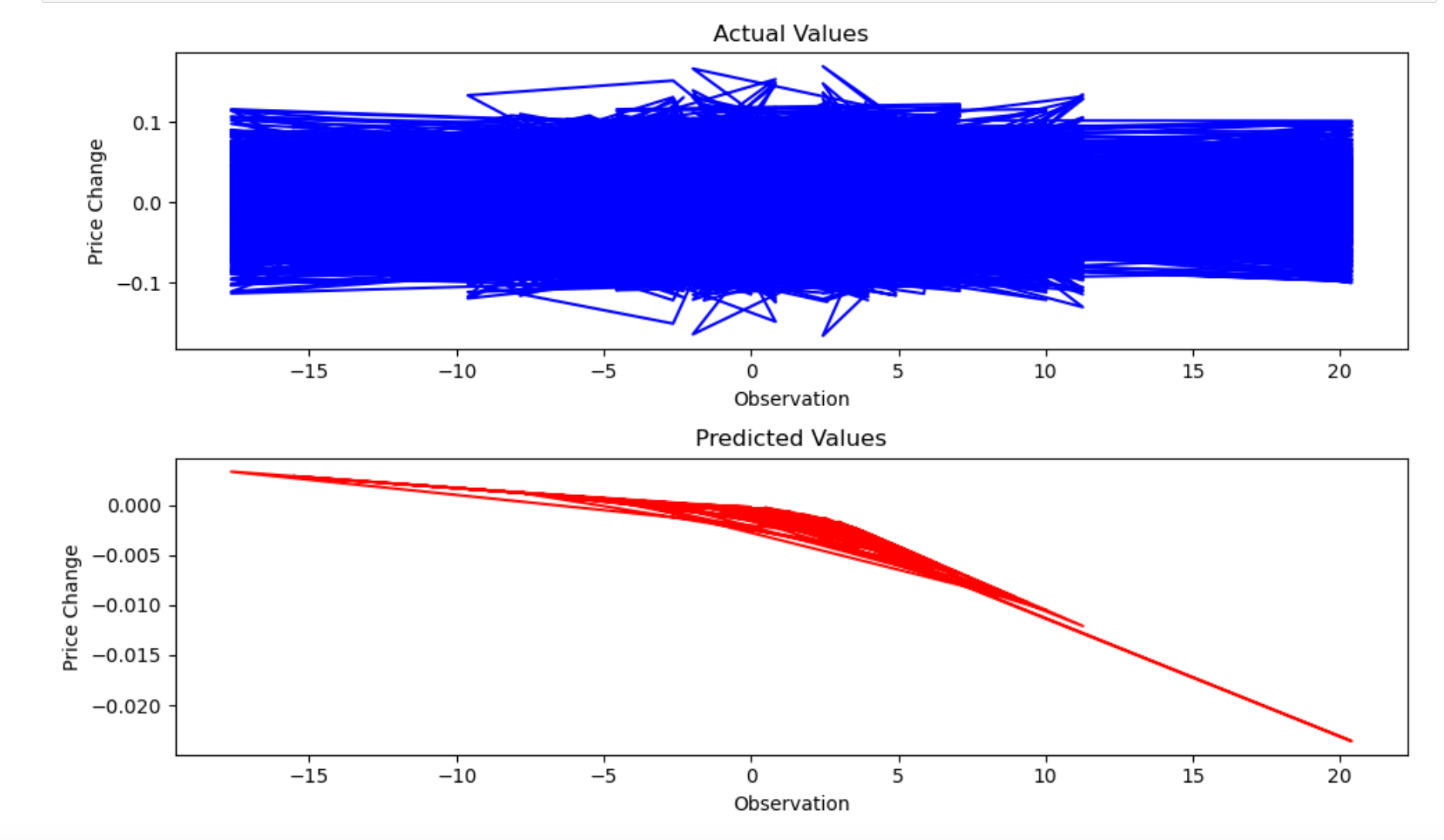
After training the RNN on our embedded post data and price deltas, we plotted the actual values against what the model predicted. The actual price changes were a wild blue tangle swinging between roughly -15% and +10%. The model's predictions? A smooth red line hugging zero. It had essentially learned to just predict "no change" every single day.
This wasn't a failure of the pipeline. The data collection, the embeddings, the model training, all of it worked the way it was supposed to. What failed was the hypothesis. WallStreetBets sentiment, at least as captured through post titles over one year, just doesn't contain a useful signal for predicting next-day SPY movement.
What We Learned
Markets Are Random
The efficient market hypothesis exists for a reason. By the time sentiment shows up in Reddit posts, the market has probably already priced it in.
Tools Matter
TextBlob was the wrong tool for financial slang. USE was better, but a domain-specific model like FinBERT might've captured more nuance.
Data Volume Is King
252 trading days is a tiny dataset for a neural network. Multi-year data with intraday granularity might tell a different story.
Negative Results Count
Showing that WSB can't predict SPY is itself a finding. Not every experiment ends with a breakthrough, and that's okay.
What We'd Do Differently
If we took another crack at this, we'd change a few things. First, we'd use a much longer time horizon, ideally five or more years of data, capturing different market environments like bull runs, bear markets, and sideways chop.
We'd also try matching sentiment to intraday price action instead of daily closes. Hourly post volume and tone might have a detectable relationship with short-term moves that gets washed out at the daily level.
On the text side, switching from just post titles to full post bodies and top comments could capture richer information. And rather than trying to predict exact price, a simpler classification approach, just predicting "up" or "down," might surface a weak signal that regression drowns out.
Finally, layering in features like trading volume, VIX levels, and options flow alongside sentiment could help isolate whether Reddit adds any marginal value on top of traditional market indicators.
But if we're being honest? The most likely outcome would be the same. The stock market doesn't care about your Reddit posts. And that's probably a good thing.